Chapter 6.2 Regression-Modelling
Simulation-based Inference for Regression
We can also use the concept of permuting to determine the standard error of our null distribution and conduct a hypothesis test for a population slope. Let’s go back to our example on teacher evaluations Chapters 6 and 7. We’ll begin in the basic regression setting to test to see if we have evidence that a statistically significant positive relationship exists between teaching and beauty scores for the University of Texas professors. As we did in Chapter 6, teaching score will act as our outcome variable and bty_avg will be our explanatory variable. We will set up this hypothesis testing process as we have each before via the “There is Only One Test” diagram in Figure 10.1 using the infer package.
Inference for regression
We usually rely on statistical software to identify point estimates and standard errors for parameters of a regression line. After verifying conditions hold for fitting a line, we can use the methods learned in Section 4.1 for the t distribution to create confidence intervals for regression parameters or to evaluate hypothesis tests.
Data
Our data is stored in evals and we are focused on the measurements of the score and bty_avg variables there. Note that we don’t choose a subset of variables here since we will specify() the variables of interest using infer.
Test statistic
Our test statistic here is the sample slope coefficient that we denote with .
Observed effect
We can use the specify() %>% calculate() shortcut here to determine the slope value seen in our observed data:
slope_obs <- evals %>%
specify(score ~ bty_avg) %>%
calculate(stat = "slope")The calculated slope value from our observed sample is .
Model of
We are looking to see if a positive relationship exists so . Our null hypothesis is always in terms of equality so we have . In other words, when we assume the null hypothesis is true, we are assuming there is NOT a linear relationship between teaching and beauty scores for University of Texas professors.
Simulated data
Now to simulate the null hypothesis being true and recreating how our sample was created, we need to think about what it means for to be zero. If , we said above that there is no relationship between the teaching and beauty scores. If there is no relationship, then any one of the teaching score values could have just as likely occurred with any of the other beauty score values instead of the one that it actually did fall with. We, therefore, have another example of permuting in our simulating of data under the null hypothesis.
Tactile simulation
We could use a deck of 926 note cards to create a tactile simulation of this permuting process. We would write the 463 different values of beauty scores on each of the 463 cards, one per card. We would then do the same thing for the 463 teaching scores putting them on one per card.
Next, we would lay out each of the 463 beauty score cards and we would shuffle the teaching score deck. Then, after shuffling the deck well, we would disperse the cards one per each one of the beauty score cards. We would then enter these new values in for teaching score and compute a sample slope based on this permuting. We could repeat this process many times, keeping track of our sample slope after each shuffle.
Distribution of under
We can build our null distribution in much the same way we did in Chapter 10 using the generate() and calculate() functions. Note also the addition of the hypothesize() function, which lets generate() know to perform the permuting instead of bootstrapping.
null_slope_distn <- evals %>%
specify(score ~ bty_avg) %>%
hypothesize(null = "independence") %>%
generate(reps = 10000) %>%
calculate(stat = "slope")null_slope_distn %>%
visualize(obs_stat = slope_obs, direction = "greater")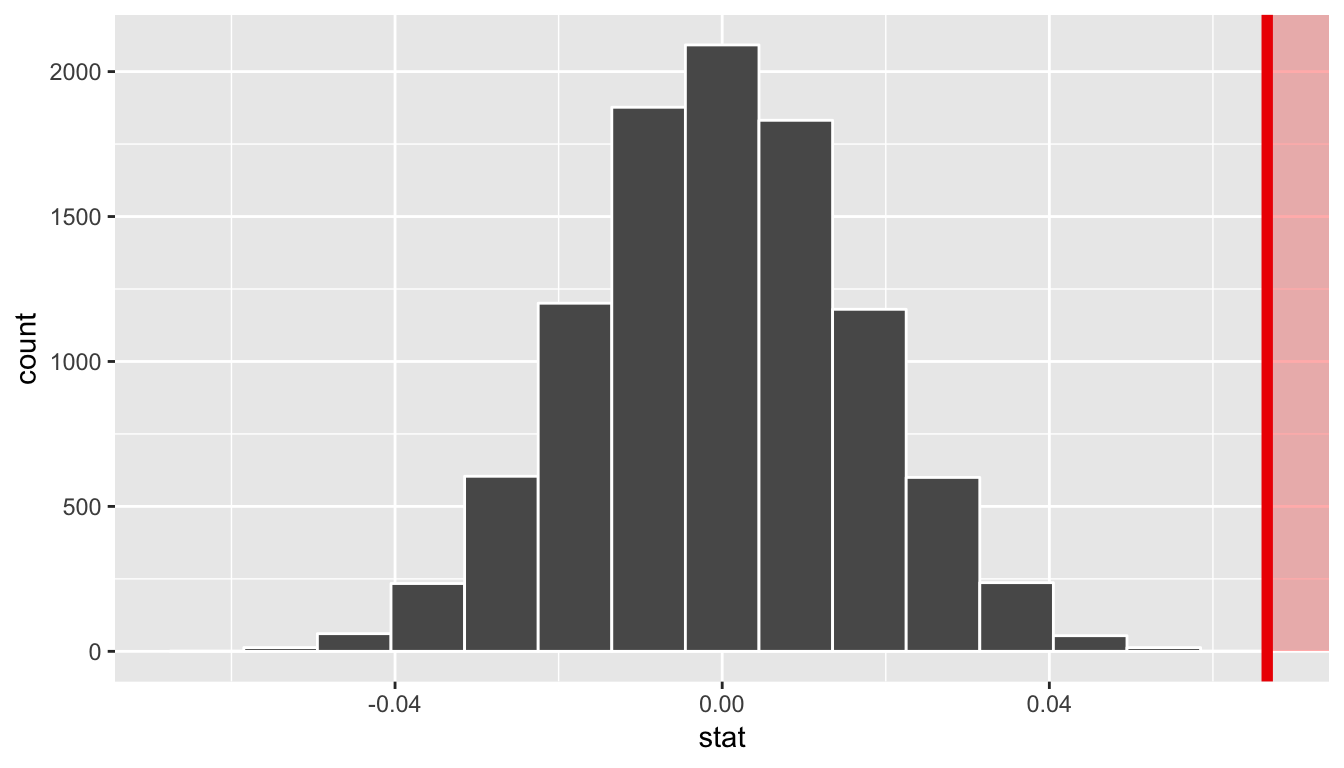
In viewing the distribution above with shading to the right of our observed slope value of 0.067, we can see that we expect the p-value to be quite small. Let’s calculate it next using a similar syntax to what was done with visualize().
The p-value
null_slope_distn %>%
get_pvalue(obs_stat = slope_obs, direction = "greater")# A tibble: 1 x 1
p_value
<dbl>
1 0Since 0.067 falls far to the right of this plot beyond where any of the histogram bins have data, we can say that we have a
-value of 0. We, thus, have evidence to reject the null hypothesis in support of there being a positive association between the beauty score and teaching score of University of Texas faculty members.
Bootstrapping for the regression slope
With the p-value calculated as 0 in the hypothesis test above, we can next determine just how strong of a positive slope value we might expect between the variables of teaching score and beauty score (bty_avg) for University of Texas faculty. Recall the infer pipeline above to compute the null distribution. Recall that this assumes the null hypothesis is true that there is no relationship between teaching score and beauty score using the hypothesize() function.
null_slope_distn <- evals %>%
specify(score ~ bty_avg) %>%
hypothesize(null = "independence") %>%
generate(reps = 10000, type = "permute") %>%
calculate(stat = "slope")To further reinforce the process being done in the pipeline, we’ve added the type argument to generate(). This is automatically added based on the entries for specify() and hypothesize() but it provides a useful way to check to make sure generate() is created the samples in the desired way. In this case, we permuted the values of one variable across the values of the other 10,000 times and calculated a "slope" coefficient for each of these 10,000 generated samples.
If instead we’d like to get a range of plausible values for the true slope value, we can use the process of bootstrapping:
bootstrap_slope_distn %>% visualize()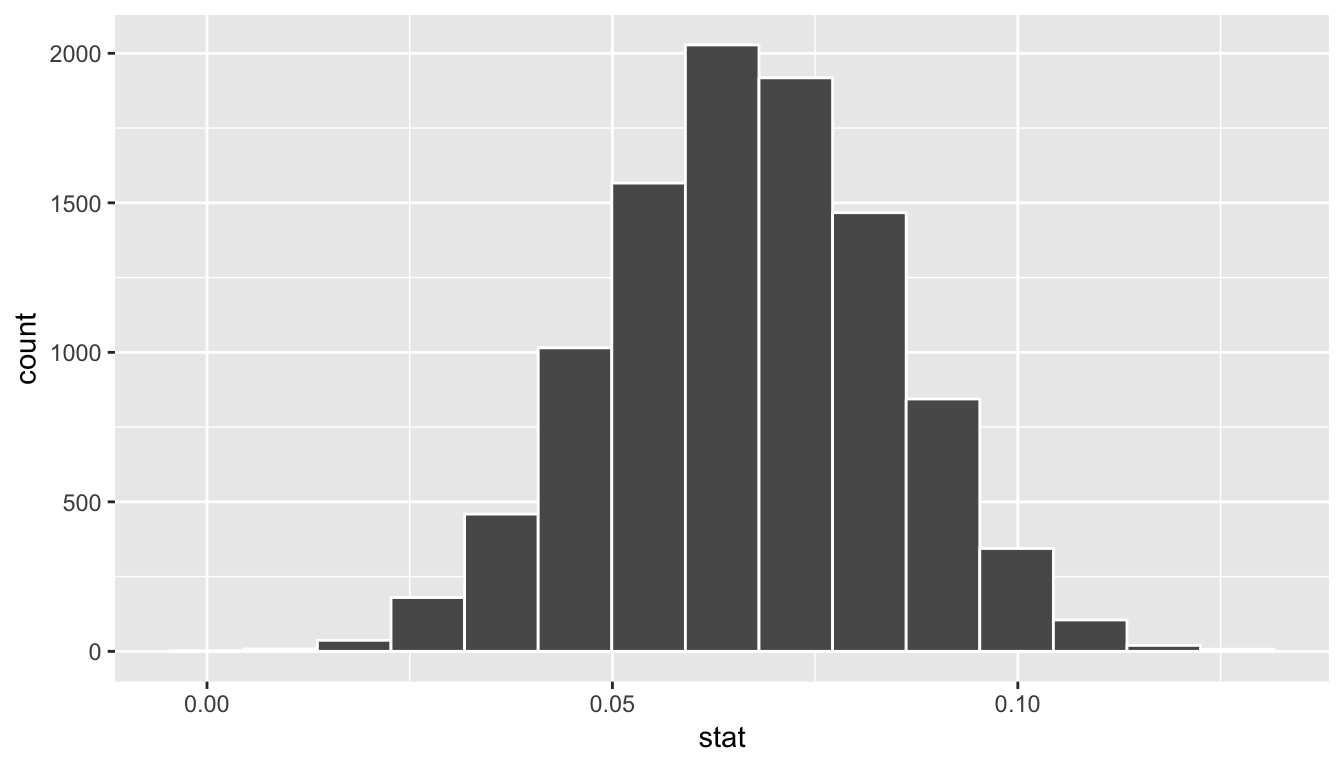
Next we can use the get_ci() function to determine the confidence interval. Let’s do this in two different ways obtaining 99% confidence intervals. Remember that these denote a range of plausible values for an unknown true population slope parameter regressing teaching score on beauty score.
percentile_slope_ci <- bootstrap_slope_distn %>%
get_ci(level = 0.99, type = "percentile")
percentile_slope_ci# A tibble: 1 x 2
`0.5%` `99.5%`
<dbl> <dbl>
1 0.0229 0.110se_slope_ci <- bootstrap_slope_distn %>%
get_ci(level = 0.99, type = "se", point_estimate = slope_obs)
se_slope_ci# A tibble: 1 x 2
lower upper
<dbl> <dbl>
1 0.0220 0.111With the bootstrap distribution being close to symmetric, it makes sense that the two resulting confidence intervals are similar.
Inference for multiple regression
Refresher: Professor evaluations data
Let’s revisit the professor evaluations data that we analyzed using multiple regression with one numerical and one categorical predictor. In particular
- : outcome variable of instructor evaluation
score
- predictor variables
- : numerical explanatory/predictor variable of
age - : categorical explanatory/predictor variable of
gender
- : numerical explanatory/predictor variable of
library(ggplot2)
library(dplyr)
library(moderndive)
evals_multiple <- evals %>%
select(score, ethnicity, gender, language, age, bty_avg, rank)First, recall that we had two competing potential models to explain professors’ teaching scores:
- Model 1: No interaction term. i.e. both male and female profs have the same slope describing the associated effect of age on teaching score
- Model 2: Includes an interaction term. i.e. we allow for male and female profs to have different slopes describing the associated effect of age on teaching score
Refresher: Visualizations
Recall the plots we made for both these models:
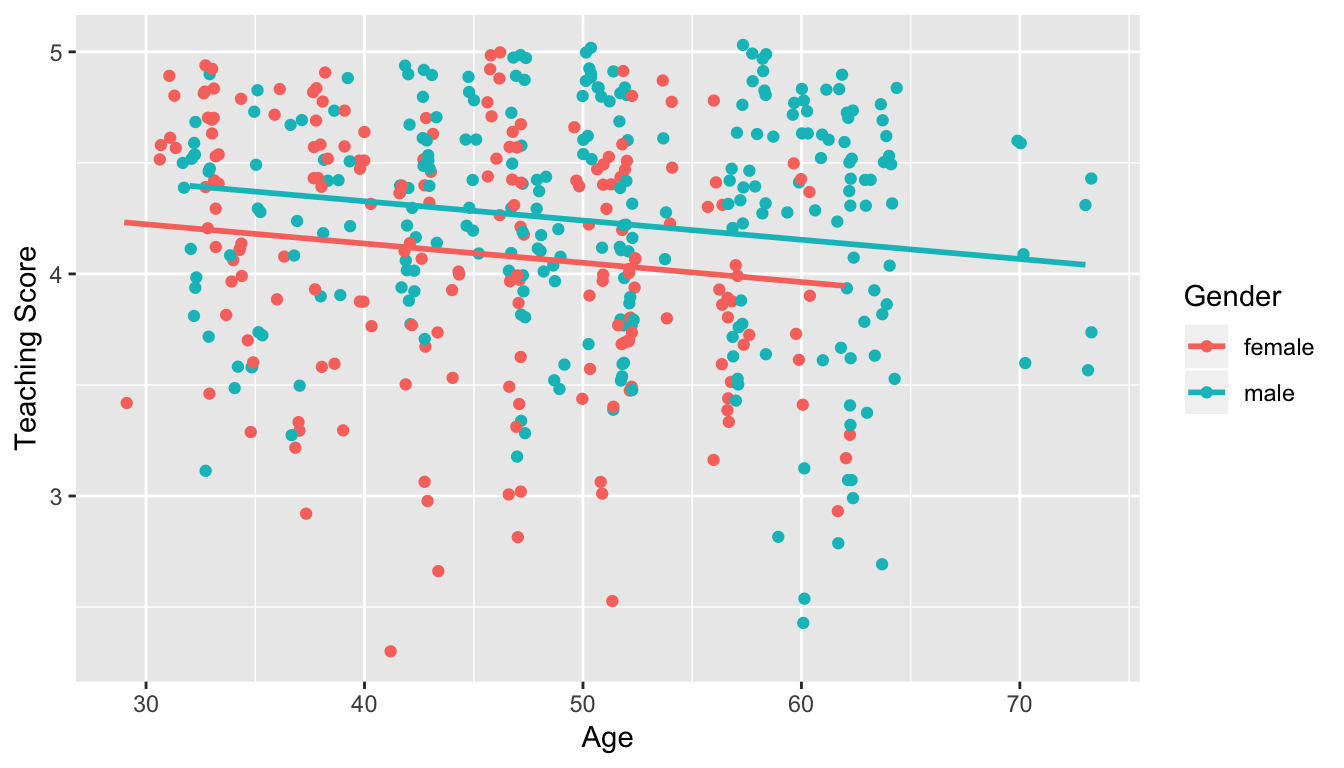
Figure 11.1: Model 1: no interaction effect included
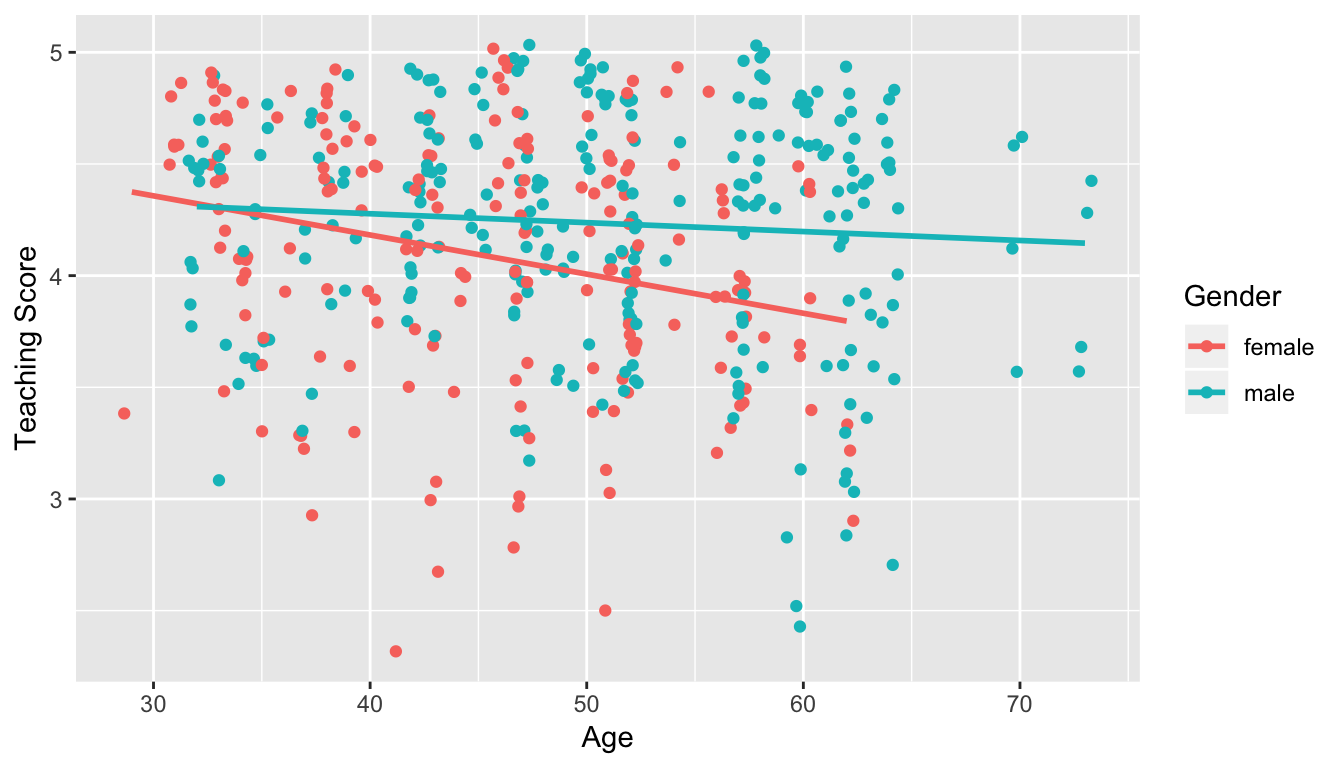
Figure 11.2: Model 2: interaction effect included
Inference map
Regression on non-Normal data with glm()
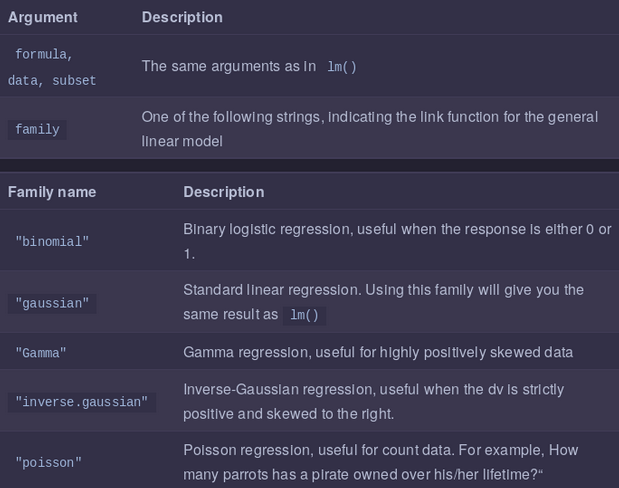
We can use standard regression with lm()when your dependent variable is Normally distributed (more or less). When your dependent variable does not follow a nice bell-shaped Normal distribution, you need to use the Generalized Linear Model (GLM).
The GLM is a more general class of linear models that change the distribution of your dependent variable. In other words, it allows you to use the linear model even when your dependent variable isn’t a normal bell-shape. Here are 4 of the most common distributions you can can model with glm():